

Обзоры [ Архив ]
- Вышла новая версия российской платформы управления мобильными устройствами «Аврора Центр»
- 20 мар 19:49
Мониторы AOC с частотой 165 Гц в XCOM-Shop - 20 мар 15:50
Планшет Blackview Tab 16 с 16 ГБ ОЗУ и четырьмя динамиками доступен с большой скидкой до 26 марта - 20 мар 15:43
Пылесосы Ilife V3sMax и H70plus доступны со скидками - 20 мар 15:08
ОС «Альт» в облаке Яндекса: надежная и экономичная ИТ-инфраструктура для бизнеса любого масштаба - 20 мар 13:41
Стартовала распродажа планшетов Teclast - 20 мар 13:05
Представлен пылесос для влажной и сухой уборки Ilife W90 - 20 мар 12:34
Электрическая зубная щетка Nandme NX7000 будет доступна с большой скидкой - 20 мар 09:54
Вертикальный беспроводной пылесос Redroad X17 подешевел - 20 мар 09:47
Tronsmart запускает портативную колонку T7 Lite с мощным басом и 24-часовым временем работы
Новости игр[ iXBT. games ]
- Xbox готовит свой магазин мобильных игр. Фил Спенсер бросит вызов Google и Apple
- У The Witcher Sirius проблемы. CDPR недовольна состоянием проекта своей студии
- Первые обзоры приключения Tchia говорят о неплохой инди-игре для PS Plus
- 91% положительных обзоров в Steam. Sun Haven – новый хит, созданный специально для фанатов Stardew Valley
- Графику Diablo 4 сравнили для всех актуальных платформ
- Релиз полной версии Torchlight: Infinite запланирован на май. Игра выйдет раньше Diablo 4, но не сильно востребована
- Интерес к Battlefield 2042 значительно вырос благодаря добавлению в PS Plus
Новости профессионального аудио[ Prosound ]
- Stam Audio SA-87T – ламповый конденсаторный микрофон
- 17 мар 09:00
Yamaha CK88 – цифровое фортепиано - 16 мар 10:00
Sennheiser Profile USB – конденсаторный USB микрофон - 16 мар 09:00
Yamaha CK61 – цифровое пианино - 15 мар 09:00
RME Fireface UFX III – звуковой USB интерфейс - 14 мар 09:00
Waldorf M 16Voice – обновлённый таблично-волновой синтезатор - 13 мар 09:00
Roland SP-404MKII 3.0 – обновление для портативного семплера - 10 мар 09:00
Arturia V Collection 9.2 – обновление набора инструментов
Подборки, скидки и купоны
- Мужские кроссовки: 10 весенних моделей на каждый день с АлиЭкспресс
- Выбираем кроссовки на распродаже: 10 практичных мужских кроссовок от разных брендов с Алиэкспресс
- 20 мар 01:26
10 налобных фонариков для работы в темных помещениях с Алиэкспресс - 18 мар 15:23
Выбираем Android TV box для своего телевизора: 10 стоящих моделей, которые актуальны весной 2023-го - 18 мар 10:35
Что делать, если пропал свет? Выбираем кемпинговые фонари на любой бюджет
Игровые блоги
- 22 мин назад 5 приключенческих компьютерных игр с красивым открытым миром
- 20 мар 22:41
Source 2 в Counter-Strike: Global Offensive. Обновление, которое ждут сильнее, чем некоторые игры
- 20 мар 15:54
Steam: Когда монополия это хорошо
- 19 мар 18:48 Музыка и звуковой ландшафт в трилогии Ведьмака
- 19 мар 14:05 Учимся играть в For Honor. Гайд на персонажа «Зачинщица»
- 19 мар 13:10 Подходящий горячий напиток сможет растопить сердце каждого и послужить началом оживленной беседы. Обзор Coffee Talk
Конференция

Профессор Борис Бабаян и г-н Хонг Фенг, главный редактор журнала Free Software, на встрече в офисе компании Эльбрус, Москва, 30 июля 2001.
Основной целью архитектуры E2K является создание Быстрого, Совместимого и Надежного Компьютера.
1 БЫСТРЫЙ И СОВМЕСТИМЫЙ КОМПЬЮТЕР
Как известно, компьютерная архитектура в значительной степени зависит от технологии.
На раннем этапе развития вычислительной техники, когда архитекторы компьютеров не могли позволить себе использование даже среднего объема аппаратных средств, все операции выполнялись строго последовательно, более того, каждая команда и операция разделялись на меньшие части, которые также выполнялись последовательно под контролем микропрограммы. Это была эра типичной CISC архитектуры.
Экспоненциальный рост технологии обеспечил компьютерному проектированию больший объем аппаратных средств, и подход микропрограммирования устарел, все операции стали выполняться аппаратными средствами, однако по-прежнему они выполнялись последовательно. Не было достаточного количества ресурсов для параллельного выполнения операций. Это была эра пре-суперскалярной RISC архитектуры с последовательным выполнением операций.
1.3 Проблема планирования при последовательном выполнении операций
Прежде чем мы перейдем к следующему этапу компьютерной архитектуры, я хотел бы немного затронуть процесс создания исполняемых двоичных кодов и способ их использования на различных компьютерных моделях.
Исполняемый двоичный код включает полное описание программного алгоритма, все операции и зависимость по данным. Это означает, что для каждой операции ясно, результаты каких операций используются для нее в качестве аргумента. Несколько менее очевидно, какие конкретные ресурсы данной компьютерной модели должны использоваться для выполнения какой-либо конкретной операции в программном коде. Другими словами, каким образом осуществляется планирование или выделение ресурсов конкретной модели для выполнения конкретных операций из двоичных кодов программы.
Для вышеописанных пре-суперскалярных CISC и RISC машин с последовательным исполнением команд ситуация была вполне очевидной. Системы команд этих компьютеров по своему характеру являются последовательными – каждая команда состоит из одной операции, и вся программа подразумевает последовательное исполнение этих команд. Для компилятора процессор с последовательным исполнением команд выглядит как компьютер с одним исполнительным устройством. Таким образом, все операции из программного кода должны быть распределены или запланированы для этого одного исполнительного устройства и должны выполняться в последовательности, определенной двоичным кодом.
Для RISC архитектуры с обособленными операциями обращения в память (LOAD/STORE RISC) было введено параллельное выполнение операции чтения (LOAD), что создавало проблему оптимизации, которая решалась и решается сейчас оптимизирующими компиляторами. Однако процесс выполнения команд все равно оставался последовательным.
До этого момента в компьютерной истории компиляторы поставщиков программного обеспечения могли выполнять планирование ресурсов (строго последовательное) во время компиляции и, что особенно важно, этот план был (и есть) справедлив для всех различных моделей (с различными техническими характеристиками ресурсов) одной и той же платформы.
Для компьютеров с последовательным выполнением команд распространяемые двоичные коды, кроме алгоритма программы, достаточно эффективно представляют подробный план использования вычислительных ресурсов для всех моделей конкретной платформы.
1.4 Компьютер с параллельным выполнением команд
С развитием технологии стали реальными компьютеры с параллельным выполнением команд. Это означает, что теперь при таком же объеме аппаратных средств те же самые последовательные двоичные коды не могут включать подробного планирования ресурсов, а только корректный программный алгоритм. Причина очень простая. Поставщики компьютеров обычно выпускают новую модель каждые полгода, в среднем, однако программные двоичные коды корректируются значительно реже. Те же самые распространяемые двоичные коды должны выполняться на нескольких различных компьютерных моделях одной и той же платформы, но для многоканального процессора, способного параллельно выполнять различные операции, конкретный план ресурсов должен быть различным для различных компьютерных моделей с различной структурой ресурсов.
Чтобы успешно справиться с этой проблемой, компьютерные архитекторы разработали аппаратные средства динамического планирования, так началась новая фаза истории развития компьютерных архитектур. Это была (и фактически есть) эра суперскаляров. Самый первый коммерческий суперскаляр был создан командой Эльбрус в 70-е годы. На западе суперскалярный подход стал популярным в начале 90х гг.
Каждый отдельный суперскалярный компьютер, используя тот же самый распространяемый двоичный код, во время выполнения программы в реальном времени в своей аппаратной части осуществляет динамическое распределение конкретных ресурсов данного компьютера (исполнительные устройства, ячейки регистрового файла и т.д.) для каждого алгоритмического объекта (операций, регистров, шин и т.д.).
В пре-суперскалярных компьютерах каждая команда кода представляет реальный физический временной шаг исполняемой программы; ссылка на регистр означает реальный физический регистр; ссылка на операцию (код операции) означает реальное физическое исполнительное устройство (хотя и единственное в случае с пре-суперскалярным компьютером).
Суперскалярная аппаратура рассматривает все ссылки в команде как ссылки на виртуальные ресурсы и динамически распределяет для них реальные ресурсы.
Последовательность команд становится виртуальной (с перестановкой последовательности выполнения операций), регистровые ссылки – виртуальными (переименование регистров), исполнительное устройство – виртуальным (выбор одного из параллельных физических устройств).
Этот динамический планировщик пытается загрузить, когда это возможно, множество имеющихся в распоряжении параллельных аппаратных ресурсов данной компьютерной модели. Во многих случаях при использовании такого подхода становится возможным исполнять несколько команд одновременно, что приводит к значительному увеличению скорости. Из двоичных кодов используется только грубый план, детальное планирование осуществляется на месте.
Многие современные суперскаляры могут исполнять до 6 команд одновременно, и среднее число команд, исполняемых за один такт, приблизительно равно двум для задач с целочисленными операциями.
Положительным моментом здесь является то, что такое управление динамическим планированием приспосабливает и планирует один двоичный код для определенной структуры ресурсов различных компьютерных моделей с одинаковой платформой. Широкое использование суперскалярной архитектуры ясно показывает, что в распространяемые двоичные коды невозможно включить эффективное планирование ресурсов для различных компьютерных моделей с аппаратными средствами, предназначенными для параллельных вычислений.
1.6 Недостатки суперскаляров
Несмотря на то, что до сих пор этот подход был достаточно успешным, он имеет существенные недостатки. Он хорошо работает для определенного уровня параллелизма аппаратных средств, когда объем аппаратуры не очень большой. Когда этот уровень превышается, задача планирования ресурсов становится настолько сложной, что ее выполнение в реальном времени ограничивает скорость компьютера.
Проблема еще более усложняется в связи с тем, что для решения задачи планирования суперскалярный процессор должен выполнить соответствующий анализ, чтобы определить, является ли определенная оптимизация ресурсов приемлемой в этот момент. Анализ, как правило, пытается установить определенные зависимости по данным, которые могут препятствовать каким-либо оптимизациям.
Время, благоприятное для суперскалярных микропроцессоров, захватывает начало 90-х гг. и сохраняется до настоящих дней. Однако сегодня эта архитектура достигла предела своих возможностей.
Так, например, в соответствии с опубликованными материалами, исполнительное устройство Alpha 464 способно работать с темпом 8 к/такт, однако устройство управления не может своевременно выполнять анализ и планирование. Поэтому разработчики Alpha 464 ввели 4 независимых программных счетчика с независимыми устройствами анализа (нет необходимости осуществлять анализ зависимостей между 4 потоками данных) для обслуживания 8-канального исполнительного устройства (SMT) – каждый программный счетчик будет использовать только часть имеющегося аппаратного параллелизма. Этот подход не должен рассматриваться как правильное решение проблемы, так как он не ускоряет единственный поток целочисленных операций, наоборот, он даже немного замедляет его.
Благодаря экспоненциальному развитию технологии мы можем предсказать очень быстрый рост существующего аппаратного параллелизма, что сделает суперскалярный подход устаревшим, а проблему планирования ресурсов еще более важной.
1.7 Метод Эльбруса
Чтобы использовать аппаратный параллелизм в большей степени и повышать быстродействие компьютеров в соответствии с развивающейся технологией, команда Эльбрус разработала новый подход, который должен обозначить следующий этап в развитии компьютерных архитектур.
Основным новшеством этого подхода является то, что задача анализа, оптимизации и планирования в существенной степени передается с аппаратного на программное обеспечение.
Такой компьютер берет распространяемые двоичные коды, скажем х86, и до их выполнения, прозрачно для пользователя, статически программно, планирует имеющиеся ресурсы этого конкретного компьютера для выполнения этой конкретной программы.
Каждая модель Эльбруса, как и суперскаляр, берет единый для всех моделей двоичный код, подгоняет, адаптирует его и выполняет планирование конкретных ресурсов данной модели. Но в отличие от суперскаляра, она осуществляет это в основном программно, а не аппаратно. Это помогает существенно повысить эффективность.
В современных суперскалярных компьютерах программное обеспечение не может этого сделать, так как реальные ресурсы не контролируются исполняемыми двоичными кодами.
Для того, чтобы наш новый компьютер смог напрямую планировать ресурсы, программный код должен непосредственно обращаться к этим реальным ресурсам, как в пре-суперскалярном компьютере. Но в отличие от него, современный компьютер включает большое число исполняемых ресурсов, работающих параллельно, поэтому теперь каждая команда должна быть достаточно широкой, чтобы включать возможную спецификацию нескольких параллельно работающих ресурсов. Как следствие, такой новый подход подразумевает использование широкой команды.
Это не означает, что вся работа по планированию обязательно должна выполняться программно. Эта схема достаточно гибкая. Мы можем реализовать часть работы по планированию в аппаратуре, а часть в программе с целью достижения самой высокой эффективности. Проблему компромиссов между статическим и динамическим планированием мы обсудим позднее.
Это выглядит как хорошо известный процесс двоичной компиляции из одной системы команд (х86) в другую (Эльбрус). Однако, в действительности, наш процесс имеет существенное отличие.
- Традиционная двоичная трансляция (ДТ) компилирует одну известную архитектуру ISA (промышленный стандарт) в другую, также известную, причем обе эти архитектуры были разработаны давно и независимо от самой двоичной трансляции. Это приводит к потере эффективности и снижению надежности (не все программы могут транслироваться правильно). Специальная аппаратная поддержка может решить (и, фактически, решает в случае с Эльбрусом) эту проблему, делая двоичную трансляцию надежной и эффективной.
- В целях эффективности все примитивные операции нового компьютера спроектированы так, чтобы обеспечивать 100% совместимость с целевой архитектурой (х86), за исключением редко используемых, которые можно эмулировать.
- Основной целью такого преобразования двоичного кода является планирование ресурсов. Основной целью традиционной двоичной трансляции является перенос кода без точного планирования ресурсов.
Ниже описывается общий способ работы такого компьютера.
Когда компьютер пытается исполнять новые двоичные коды х86, система (специальные аппаратные средства и системное программное обеспечение) автоматически обнаруживает отсутствие сохраненного скомпилированного на уровне двоичных кодов плана и начинает динамическую компиляцию и выполнение. Он создает оптимизированную версию скомпилированного кода и запоминает ее для будущего выполнения. В случае повторного вызова той же самой программы для ее выполнения будет использоваться уже оптимизированный код.
Очень важно, что весь процесс является прозрачным для пользователя. Для него это выглядит так, будто он использует традиционный компьютер с х86 архитектурой.
Другой важной особенностью предложенной архитектуры является то, что специальная аппаратная и программная поддержка обеспечивает высокоэффективное и 100-процентно надежное выполнение вычислений:все коды, выполняемые на обычном х86 компьютере, работают точно также на новом компьютере.
Суть нашего подхода заключается в том, что мы вводим два интерфейса:
- первый интерфейс – это общий дистрибутив, открытый для всех. Например, x86 или специально разработанный Переносимый Объектный Код (РОС);
- Второй интерфейс – это архитектура ISA каждой модели, только для внутреннего пользования, показывающая компилятору все ресурсы;
c локальной трансляцией с одного интерфейса в другой и локальным планированием ресурсов во время компиляции:
При создании суперскалярных компьютеров возникает дилемма. С одной стороны, нужно иметь возможность выполнять более сложное планирование для более сложной и параллельной аппаратуры как сегодня, так и в будущем. С другой стороны, необходимо уменьшать сложность аппаратуры. Это выглядит несколько противоречиво. Таким образом, естественным решением является перенос этой сложной работы планирования в программное обеспечение. Перенося ее в программы, мы не увеличиваем объем работы, наоборот, мы даже значительно уменьшаем его, так как мы делаем это только один раз во время компиляции, в то время как суперскаляр делает это неоднократно.
Мы могли бы предположить следующее возможное решение. Включить в дистрибутив больше информации, что помогает упростить аппаратное планирование. К сожалению, это не работает. Это противоречит проблеме двоичной совместимости. Мы ничего не можем изменить в двоичных кодах х86. Но даже если нам хватит смелости, чтобы ввести новые двоичные коды, вряд ли возможно располагать достаточной информацией полезной для любых возможных будущих моделей с различными размерами и структурами ресурсов. Каждой новой ресурсной структуре необходима определенная оптимизация планирования и, как и в оптимизирующем компиляторе, каждой оптимизации необходим свой собственный специальный анализ. Таким образом, получить дистрибутив, подходящий для всех будущих неизвестных режимов – просто научная фантастика.
Итак, похоже, что единственным возможным решением проблемы является подход Эльбруса.
Его можно назвать “ExpLicit Basic Resources Utilization Scheduling”, (Явное планирование использования основных ресурсов), или сокращенно ELBRUS. И этот подход должен ознаменовать новый период развития технологии в компьютерной индустрии.
1.8 Компромисс между динамическим и статическим планированием
Сейчас мы хотели бы обсудить правильный компромисс между статическим и динамическим планированием.
Как уже указывалось ранее, для компьютеров с последовательным исполнением команд статическое планирование не представляет проблемы.
Для небольшого числа устройств, способных работать параллельно, суперскалярный динамический планировщик ресурсов работает хорошо и не ограничивает скорость выполнения операций.
Но для большего числа параллельных устройств задача анализа алгоритма и планирования ресурсов возрастает квадратически. Эта работа должна выполняться в каждом такте и, таким образом, это быстро превращается в фактор, ограничивающий скорость, который может привести к ее снижению.
С другой стороны, статический планировщик имеет другие недостатки.
- Компьютер затрачивает какое-то время на компиляцию.
- Необходимо выделить некоторое дисковое пространство для оптимизированного скомпилированного кода часто используемых программ.
- Хотя он может обеспечить самое эффективное использование ресурсов со статическим поведением, он не может учитывать реальные динамические ситуации, промахи кэша и т.д.
Даже для современных программ время, затраченное на компиляцию составляет лишь небольшую часть всего времени, затраченного на выполнение операций. Это было подтверждено опытом фирмы Transmeta. Микропроцессор Crusoe использует только динамическую компиляцию – он компилирует каждую программу с нуля до того, как ее выполнять, и даже при таком подходе они имеют вполне допустимую скорость.
В случае с Эльбрусом мы используем статически скомпилированную хорошо оптимизированную версию кода вообще без таких небольших потерь.
Стремительное развитие компьютерных технологий позволяет предположить, что вскоре компьютер будет выполнять намного больше команд за единицу времени, и тогда соотношение между числом динамически исполняемых операций за один прогон программы и числом операций (статических) в том же самом программном коде суущественно увеличится. Это сдвинет точку компромисса в пользу метода программного планирования.
Более того, размер этого пространства находится под контролем системы, так как в соответствии с некоторой стратегией редко используемые оптимизированные коды могут удаляться и снова перекомпилироваться при необходимости.Дисковое пространство для скомпилированной программы довольно небольшое по сравнению с емкостью современных дисков, причем со временем оно все больше будет увеличиваться.
Если поведение аппаратных ресурсов может быть статически точно спрогнозировано, метод программного планирования обеспечивает практически наилучшее использование ресурсов и эффективность кода. В этом случае компилятор может проанализировать большую часть программы и оптимизировать ее почти до возможного предела. В отличие от аппаратного планировщика суперскаляров он делает это только один раз для каждой конкретной части программы, в то время как суперскаляр повторяет ее всякий раз, когда этот код выполняется, при этом увеличивается энергопотребление и понижается скорость выполнения операций.
Есть только один параметр вычислительного ресурса, чье поведение сложно, если вообще возможно, предсказать точно во время компиляции. Это время выполнения считывания в системе памяти.
Кроме традиционных способов улучшения этого параметра, например, такого, как иерархия памяти (кэши), в проекте Эльбрус был реализован ряд новых идей, обеспечивающий уменьшение потерь и сведение их к пренебрежимо малому значению. Для этого были использованы следующие усовершенствования:
- перестановка операций чтения из памяти за пределы собственного базового блока, а также выше потенциально конфликтующих операций записи (с использованием спекулятивных операций чтения и буфера динамического сравнения адресов);
- большой регистровый файл для сохранения предварительно считанных данных;
- подготовка переходов для предварительной подкачки целевых команд;
- буфер предварительной подкачки (буфер FIFO для асинхронной предварительной загрузки элементов массива)
- (элемент динамического планирования);
- явная обработка промахов кэша программным кодом, обеспечивающим два отдельных плана: для попаданий и для промахов.
Такая организация с использованием предварительной подкачки и явного планирования сводит задачу предсказания задержки обращения в память к худшему случаю и делает статическое планирование очень эффективным.
Благодаря использованию вышеописанных приемов в редких случаях для предсказания промахов может применяться традиционный метод Scoreboarding, который также является частью динамического планировщика.
В результате, сегодня реальный компромисс между динамическим и статическим планированием в значительной степени склоняется в пользу статического планирования, и с развитием технологии этот процесс будет все более очевидным.
1.9 Преимущества архитектуры E2K
Кроме высокой скорости данная технология имеет множество сильных преимуществ.
1. Простота. В результате удаления из аппаратуры таких сложных механизмов, как перестановка последовательности выполнения операций, переименование регистров, спекулятивное выполнение и предсказание переходов, компьютер концептуально становится таким же простым, как пре-суперскалярный RISC.
2. Небольшой размер кристалла. По той же самой причине, что и выше, размер кристалла значительно меньше.
3. Хорошее соотношение стоимость/производительность. Результат высокой скорости и небольшого размера кристалла.
4. Высокая тактовая частота. Простота идеи делает возможной реализацию высокой тактовой частоты.
5. Лучше используется высокая технология. Становится понятным, как наиболее эффективно использовать большое количество транзисторов.
6. Более эффективная компиляция. При всей сложности процесса компиляциив в Е2К проще достичь высокой эффективности, так как, в отличие от суперскаляра, известно точное поведение ресурсов.
7. Стандартный способ проектирования. Простота устройства управления и свободное изменение системы команд для различных моделей приводит к вполне обычному способу проектирования. Мы проектируем сначала пути обработки данных компьютера без каких-либо ограничений со стороны блока управления. Они могут проектироваться с самой высокой производительностью в соответствии с их внутренней логикой. Затем мы разрабатываем систему команд, которая полностью использует эти пути обработки данных. Это означает, что:
- процесс проектирования становится проще: пути обработки данных и логика управления разрабатываются независимо;
- пути обработки данных (и, как результат, сам компьютер) могут разрабатываться с самой высокой эффективностью.
8. Проверка (и доказательство корректности) аппаратного обеспечения более простая. В суперскаляре одна и та же команда работает в различных условиях в зависимости от различной динамической предыстории различных прогонов. Довольно длинная предыстория может повлиять на выполнение этой команды. Для хорошего тестирования мы должны использовать большое количество этих комбинаций. В нашем случае все зависимости находятся в пределах нашего короткого конвейера.
9. Адаптируемость. Эта система обеспечивает самую лучшую адаптируемость, так как задача подгонки к определенной модели передается программному обеспечению.
10. Многоплатформная реализация. Благодаря использованию двоичной компиляции можно поддерживать несколько архитектурных платформ в одном и том же компьютере.
1.10 Альтернативные методы
Здесь мы хотели бы обсудить другие попытки преодолеть ограничения традиционного суперскалярного метода. Существует только два таких случая в индустрии: IA-64 фирмы Intel и Crusoe фирмы Transmeta..
1.10.1 Intel IA-64
Основной принцип работы IA-64 очень близок к первым суперскалярам – не используется перестановка последовательности выполнения команд, не осуществляется переименование регистров, отсутствует неявное спекулятивное выполнение операций. Компьютер выполняет все команды по очереди, но, используя логику группирования, пытается выполнить столько последовательных команд одновременно, сколько это возможно без нарушения зависимости по данным. От суперскаляра он также унаследовал механизм предсказания переходов.
Основное отличие от суперскаляра заключается в том, что IA-64 сделал доступными (ввел в распространяемую систему команд) все внутренние методы, используемые суперскаляром с перестановкой последовательности выполнения операций, для динамического планирования локальных ресурсов. Это:
- спекулятивное выполнение команд, включая перестановку операций считывания из памяти;
- логика группирования;
- буфер динамического сравнения адресов и т.д.
Используя эти методы, компилятор, формирующий дистрибутив, может выполнять почти всю работу по планированию, которую суперскалярный компьютер, реализующий перестановку последовательности выполнения операций, выполняет динамически в каждой модели в реальном времени.
В IA-64 последовательность команд дистрибутива разделяется на группы, состоящие из независимых команд, которые могут исполняться одновременно. Как будет показано позднее, этот способ может быть эффективен только при наличии реально имеющихся ресурсов определенной модели.
Для правильного использования имеющихся свободных ресурсов компилятор вводит достаточно спекулятивных и предикатных операций. В соответствии с имеющимися ресурсами и реальными задержками системы памяти компилятор переставляет некоторые операции чтения, используя спекулятивный режим или буфер динамического сравнения адресов. Все эти оптимизации имеют реальный смысл, когда мы знаем реально существующие ресурсы.
Каждая модель может выполнять не всю группу команд, а только ее часть в соответствии с ресурсами, которыми располагает модель в данный момент. Но компьютер не может выполнять команды из различных групп в том же такте. Это единственный возможный путь адаптации к конкретной модели. Позднее мы покажем, что и этого недостаточно.
Неправильным здесь является то, что дистрибутив представляет собой код, оптимизированный только для одной конкретной модели. IA-64 исключил из суперскалярного подхода механизмы адаптации к конкретной модели без какой-либо замены (мы не можем рассматривать выполнение части группы команд как нечто адекватное). Это опасно, особенно с точки зрения быстро развивающейся технологии производства кристаллов, ставящей перед разработчиками архитектуры большую и сложную задачу.
Авторы IA-64 либо предположили, что все будущие модели будут основываться на одной и той же схеме ресурсов (что нереально), либо решили, что всех устроит большая потеря эффективности при работе программы, скомпилированной для той или иной модели. Фактически это означает, что компьютеры IA-64 будут (обычно) использовать код, оптимизированный для какой-либо предыдущей модели с соответствующей потерей эффективности. Таким образом, для обычного пользователя из официально объявленных значений мы должны вычесть не менее 25% скорости.
Как легко можно понять из вышеприведенного обсуждения, проблема адаптируемости в IA-64 была разрешена на очень низком уровне. А эффективная совместимость вообще не была затронута (собственно в IA-64). Эти две проблемы достаточно близки друг другу.
IA-64 для совместимости предлагает реализацию обеих (x86 и IA-64) систем команд в одном микропроцессоре (“два в одном”). Помня о плохой адаптируемости IA-64, естественное обобщение решения проблемы совместимости в IA-64 для будущих моделей будет состоять во включении всех предыдущих моделей в настоящий микропроцессор.
IA-64 выглядит как искусственная мелкая копия E2K, реализованная даже без понимания глубоких корней, ведущих к этому решению.
Рассмотрим несколько примеров плохой адаптируемости IA-64:
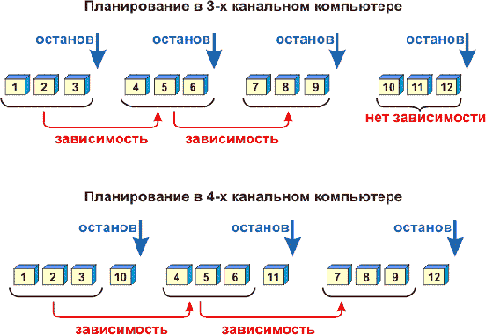
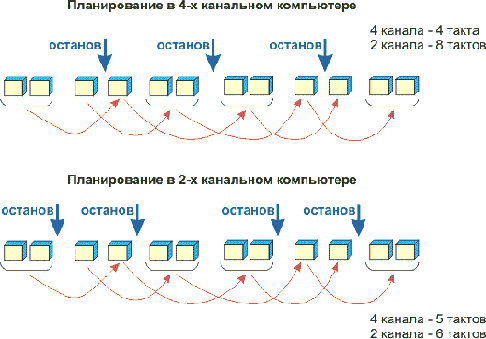
1. На двух рисунках ниже приведены примеры, которые ясно показывают, что без точного знания “ширины” компьютера невозможно эффективно осуществить группирование команд. На рисунке представлена последовательность команд, зависящая от “ширины” компьютера. Стрелки показывают конец групп. Из первого примера следует, что для эффективного планирования в случае с трехканальными или четырехканальными компьютерами необходимо выбрать различный порядок команд, в противном случае потери составят до 25%.
Чтобы получить эффективное планирование для четырехканального и двухканального компьютеров, показанных на втором рисунке,нам необходимо поменять позиции останова, хотя последовательность операций является оптимальной для обоих случаев. Если позиции останова не менять, потери снова составят 25%.
2. При использовании подхода IA-64 трудно вводить регистровые кластеры, как это делается в процессорах Эльбрус-3, Е2К и Alpha. Система с кластерами требует специального способа планирования команд, выполняемых в каждом такте. В этом случае недостаточно разбивать команды на группы, запускаемые в одном и том же такте. Необходимо дополнительно размещать каждую команду из группы в конкретный кластер. Эта работа требует некоторого дополнительного анализа зависимостей. Во избежание лишних блокировок необходимо выявить все зависимости отдельных команд между соседними группами (а это большой объем анализа) и запланировать зависимые команды для размещения в одном и том же кластере.
Этой информации нет в исходном коде IA-64, поэтому для эффективного использования кластерной структуры нужно либо изменить систему команд, либо вернуть сложный анализ и планирование в аппаратуру (как в суперскаляре). Даже если мы изменим систему команд и используем информацию о кластерах, это сработает только для конкретной модели.
Напрашивается вывод: либо придется вернуть анализ и планирование в аппаратуру, и в этом случае у IA-64 будут такие же недостатки, как и суперскаляра, либо будет полностью потеряна адаптируемость.
3. Такая же ситуация происходит и с двухэтажным исполнительным устройством, как в Е2К. Мы должны разместить связанную команду в двухэтажное устройство, что требует использования специальной аппаратуры для анализа и планирования.
Такой же вывод, что и выше.
4. Для каждой конкретной модели с определенной шириной команды компилятор должен выбрать соответствующий уровень спекулятивного исполнения. Избыток спекулятивности для моделей с узкой командой означает
уменьшение скорости вследствие избыточного выполнения уменьшение скорости вследствие избыточного выполнения операций. Низкий уровень спекулятивного исполнения для моделей с широкой командой означает уменьшение скорости в результате неполного использования ресурсов.
Спекулятивные операции включены в код IA-64. Это означает, что код уже ориентирован на определенную ширину компьютера. Это снова говорит о недостатке адаптируемости.
5. С приходом 0,1µ технологии будут разработаны сильно связанные кристаллы с несколькими ядрами. Для использования этого преимущества дистрибутив IA-64 необходимо перекомпилировать. И опять – недостаток адаптируемости.
Может показаться, что позднее Intel может попытаться исправить недостатки архитектуры IA-64 за счет ввода метода двоичной компиляции, как в Е2К. В принципе, это возможно, однако приоритет в этой области принадлежит авторам Е2К.
Схема Е2К предполагает наличие 2-х интерфейсов (как было сказано выше): дистрибутивного двоичного кода и системы команд конкретной модели с двоичной компиляцией в промежутке.
Однако система команд IA-64 плохо подходит для обеих случаев.
Она плоха в качестве дистрибутива, так как состоит из множества деталей, зависящих от схем ресурсов конкретных моделей, таких как спекулятивное выполнение, буфер динамического сравнения адресов и т.д., которые не должны быть представлены в общем дистрибутиве.
Она также плоха как система команд конкретной модели, так как не обеспечивает доступа к физическим ресурсам.
Transmeta приняла и реализовала эту технологию более последовательно. Но они используют эту технологию, имея другую цель.
Они используют эту технологию для создания компьютера с низкой рассеиваемой мощностью. Этот пример показывает большую мощь и гибкость технологии.
Команда микропроцессора Crusoe имеет четыре слога (команда Эльбруса имеет 16 слогов; микропроцессор может выполнять до 23 операций одновременно). Микропроцессор использует только динамическую двоичную компиляцию (Эльбрус использует также и статическую компиляцию). Так что у Crusoe достаточно оснований, чтобы наращивать свою скорость.
Общую надежность вычислений можно разделить на программную и аппаратную составляющие.
2.1 Аппаратная надежность
Команда Эльбруса имеет большой опыт (3 поколения компьютерных систем и более 25 лет работы) проектирования высоко надежной аппаратной логики, но, по некоторой причине, она не включена сейчас в проект Е2К, хотя это можно легко сделать при необходимости.
Здесь мы хотели бы представить основные принципы надежности аппаратного обеспечения Эльбруса.
Все устройства имеют дополнительные схемы, обнаруживающие единичные отказы аппаратуры, как нерегулярные, так и постоянные, и передающие сигнал об их обнаружении в остальную часть системы.
Каждый блок имеет другие специальные схемы, которые в случае поступления такого сигнала, автоматически без программной поддержки, отключает все линии связи от неисправного блока.
Затем остальная часть системы начинает программный процесс восстановления. Компьютеры линии Эльбрус представляют собой многопроцессорные системы, поэтому в большинстве случаев имеется достаточное количество устройств, чтобы успешно продолжить работу.
Такой тип организации обеспечивает не только высокий уровень надежности (система в целом не имеет простоев даже в случае низкой надежности отдельных элементов аппаратуры), но и высокий уровень достоверности результатов.
Система может иметь нерегулярные отказы – наиболее вероятно, что она успешно восстановится и продолжит вычисления.
Если система не может восстановиться или отказ носит постоянный характер, наиболее вероятно, что неисправный блок будет исключен из системы, а остальная часть системы продолжит выполнение программы, и, в конечном итоге, выдаст правильный результат.
В чрезвычайно редких случаях система может передать сигнал о невозможности восстановления или продолжения выполнения программы.
Таким образом, вероятность того, что система выдаст какой-либо неправильный результат без передачи сигнала о неисправности, практически равна нулю.
2.2 Программная надежность
Программная надежность означает, что влияние программы с ошибками или отклонениями на остальную часть системы должно быть исключено.
Надежность программного обеспечения означает защищенное программирование. Оно обеспечивает:
- более простую отладку программы;
- существенное сокращение времени до выхода программных продуктов на рынок;
- существенное уменьшение вероятности ошибок в уже готовых программных системах и, как результат, уменьшение вероятности возникновения довольно опасных последствий;
- исключение опасности вирусов что, может быть, наиболее важно.
Мировое сообщество ежегодно теряет много миллиардов долларов в результате плохой реализации этих свойств в компьютерных системах.
И очень забавно, что сильное средство против этого было известно всем, может быть, с самого начала развития компьютерной индустрии. Его реализация достаточно проста и прямолинейна. Многие системы языков высокого уровня имеют очень убедительный практический опыт. Команда Эльбрус имеет опыт, насчитывающий три поколения компьютеров и 25 лет работы по созданию целой системы – языка высокого уровня и операционной системы.
Для ввода этой системы необходимо нарушить совместимость, но это нарушение будет не очень значительным. Нам кажется, что небольшая несовместимость, позволяющая избежать огромных потерь от вирусов, выглядит более чем позволительной.Она, может быть, даже меньше, чем несовместимость между двумя версиями одной и той же программы. И мы можем предложить очень плавный и безболезненный переход на новую систему.
Смысл прост – типы данных (для защищенности – только указатели) должны обрабатываться правильно.
Это правило соблюдают все, кроме хакеров с их злоумышленными намерениями. Однако система должна проверять правильность обработки указателей, чтобы помочь отладке программ и остановить хакеров.
Чтобы более детально обсудить этот предмет, необходимо отдельно рассмотреть систему памяти и файловую систему.
В настоящее время в популярных языках указатели представлены явно целым числом. Пользователь может присвоить целое число типу данных “указатель”. Это нарушает защиту памяти.
В результате две различных процедуры программ в одном и том же виртуальном пространстве не защищены друг от друга. Это означает:
- даже внутри одной и той же программы – плохое средство отладки;
- отсутствует защита памяти в одном и том же виртуальном пространстве.
Различные программы обычно используют отдельные виртуальные пространства, при этом теряется эффективность, затрудняется связь и использование общих данных.
Чтобы справиться с проблемой, некоторые языки, такие как Java, вообще исключают указатели из языка. Но это делает язык не универсальным, а программирование – менее эффективным.
Мы используем совершенно другой подход. Его можно рассматривать как расширение подхода Java. Мы осуществляем аппаратную поддержку данных и указателей процедур, что делает их использование очень эффективным.
Указатель процедуры состоит из ссылки на контекст и кода и используется для вызова процедур. Процедурный механизм (команды вызова/возврата и механизм передачи параметров) поддерживается аппаратно как элемент защиты памяти. Контекст процедуры поддерживается с помощью указателей.
В Е2К все указатели помечены специальным разрядом, который помогает аппаратуре проверять правильность обработки указателей. Е2К не нужна какая-то специальная система памяти – вместо сохранения этого бита используется некоторые дополнительные комбинации в коде ЕСС.
Основную стоимость такой аппаратной защиты составляют два дополнительных разряда на каждые 32 разряда в кристаллах ЦП и кэш-памяти. Это практически не замедляет скорость выполнения операций.
Опыт Эльбруса показывает, что эта схема:
- существенно уменьшает время отладки (до 10 раз);
- уменьшает вероятность пропуска необнаруженной ошибки в уже поставленном программном обеспечении. Мы нашли более 30 ошибок в эталонных тестах SPEC, которые считаются хорошо отлаженными программами;
- обеспечивает превосходную защиту между отдельными процедурами в одном виртуальном пространстве.
Вы можете безопасно выполнять в одном виртуальном пространстве любую загружаемую программу, общаться с ней через параметры без опасности для остальной части программы и данных, находящихся в том же виртуальном пространстве.
Это обеспечивает хорошую поддержку реализации отличной защиты в файловой системе.
2.2.2 Файловая система
Файловая система традиционных операционных систем находится в более худшей ситуации. Тип данных “указатель” здесь вообще не вводится. Приходится использовать обычную символьную строку (стринг) в качестве имени файла или указателя файла. Этот стринг описывает путь к названному файлу из корня, общего для всего компьютера.
Такая организация создает весьма благоприятную ситуацию для хакеров, пытающихся ввести вирусы.
Предположим, что мы загрузили программу из Internet и собираемся передать этой программе файл параметров. Более того, возможно, внутри файла параметров есть некоторые стринги, представляющие имена других файлов в файловом пространстве. Вот почему загруженной программе необходимо дать корень нашего файлового пространства – это позволит запускать такой тип программ и иметь доступ к файлам параметров и их производным в нашем файловом пространстве. Мы даже не можем ограничить доступ к файлам с помощью механизма контроля права доступа, просто потому, что загруженная программа запускается под нашим именем.
Сложно представить ситуацию, более благоприятную для хакеров и вирусов.
Кроме зашиты от вирусов, традиционная организация файловых систем содержит проблемы и с точки зрения обычной практики программистов.
Предположим, что программист (не хакер) создал программу, скажем, в компьютере А в файловом пространстве компьютера А, а затем эта программа была перенесена и выполнена в компьютере В.
Что произойдет в этом случае? Эта программа будет выполнена в другом окружении, что является неправильным с точки зрения обычной программистской практики. Только параметры должны быть переданы пользователем, который вызвал ее, но остальное окружение должно оставаться тем же самым.
Таким образом, это неудобно для программистов и удобно для хакеров.
Как уже говорилось, решение Эльбруса основывается на введении в файловую систему двух типов указателей: указателя файла и указателя программы.
Для реализации этого метода не требуется никакой дополнительной аппаратуры. Все указатели размещаются только в словарях. Но в отличие от корневой системы, эта файловая система основывается на сети. Указатель программы состоит из ссылки на файл кода программы и ссылки на словарь, представляющий собой файловый контекст данного конкретного программного кода. В частном случае, контекстный словарь всех программных файлов может совпадать со старым корнем. Таким образом, новую систему можно рассматривать как строгое расширение традиционной системы.
В этой системе контроль прав доступа становится необязательным. Контроля указателя вполне достаточно для сильной и очень удобной для пользователей файловой системы.
Очевидно, что вирусы вообще не могут существовать в такой системе. Предположим, что в системе реализованы межкомпьютерные файловые указатели.
Предположим также, что компьютер и пользователь А загрузили из компьютера В программу, созданную пользователем В. Теперь эта программа имеет доступ только к параметрам, переданным явно пользователем А, и, возможно, к своему собственному контексту, если таковой имеется в компьютере В (через межкомпьютерную ссылку). Невозможно нарушить файловую защиту или инфицировать какие-либо файлы из компьютера А.
Хотя эта система существенно отличается от традиционной с точки зрения реализации, фактически она может быть реализована с очень незначительной несовместимостью с точки зрения пользователя. Более того, мы можем предложить достаточно плавный путь ее ввода.
Между прочим, невозможно решить проблему вирусов без введения некоторой несовместимости, просто потому, что сегодня любой вирус является вполне легальной программой, и наоборот, ограничение на выполнение вирусной программы прямо противоречит всем руководствам по пользованию языками и системами.
Наш подход абсолютно исключает опасность вируса, в отличие от сегодняшней бесконечной практики, когда люди ждут появления нового вируса и создают средство борьбы только с этим конкретным вирусом, продолжая ожидать появления следующих вирусов.
Существует два способа инфицирования системы вирусами: через ошибки в системном программном обеспечении и через вышеописанный дефект проектирования файловой системы.
Эльбрус учел оба пути. Ошибки в системе можно значительно уменьшить с помощью нашей системы защиты памяти, кроме того, у нас есть хорошее предложение по улучшению файловой системы.
Эльбрус имеет богатый опыт реализации и использования этой системы (более 25 лет и 3 поколения компьютеров).
Мы знаем, что ввод этой системы в реальную жизнь является сложной задачей, однако устранение вирусной опасности является проблемой, требующей еще большего внимания.
Копирование и распространение настоящего материала целиком разрешено без выплаты авторского гонорара при условии сохранения авторского права и указания на данный источник.
Команда Эльбрус имеет богатый и яркий опыт практического проектирования серийных универсальных вычислительных систем с высоким уровнем безопасности.
Высокий уровень безопасности обеспечивает полную защиту от вирусов и, кроме того, значительно улучшает возможности отладки, особенно в больших системах программного обеспечения.
Такая технология обеспечивает преимущество и имеет сегодня жизненно важное значение для всего компьютерного мира.
Для того чтобы реализовать эту технологию в широком масштабе. не нужно проводить научных исследований, а нужно приложить большие конструкторские усилия.
Такая задача отвечает интересам всего свободного творческого компьютерного сообщества.
Мы будем рады принять участие в дискуссии, которая поможет в осуществлении этой идеи.
– Борис Бабаян






