

В данном разделе будут рассмотрены основные типы данных в С++, эти типы данных ещё называются встроенными. Язык программирования С++ является расширяемым языком программирования. Понятие расширяемый означает то, что кроме встроенных типов данных, можно создавать свои типы данных. Поэтому в С++ существует огромное количество типов данных. Мы будем изучать только основные из них.
В таблице 1 представлены основные типы данных в С++. Вся таблица делится на три столбца. В первом столбце указывается зарезервированное слово, которое будет определять, каждое свой, тип данных. Во втором столбце указывается количество байт, которое отводится под переменную с соответствующим типом данных. В третьем столбце показан диапазон допустимых значений. Обратите внимание на то, что в таблице все типы данных расположены от меньшего к большему.
- Тип данных bool
- Составные типы
- Символьный тип
- Целочисленный тип
- Диапазоны значений целочисленных типов
- Вещественный тип
- Диапазоны значений вещественных типов
- Логический тип
- Тип void (пустой)
- Объявление переменных
- Тип данных char
- Типы данных
- Целочисленные типы
- Суффиксы целочисленных типов
- Определение чисел в различных системах
- Числа с плавающей точкой
- Символы
- typedef
- Размер типов данных
- Типы данных
- Логический тип
- Целочисленные типы
- Различные системы исчисления
- Числа с плавающей точкой
- Размеры типов данных
- Символьные типы
- char
- wchar_t
- Спецификатор auto
- Целочисленные типы данных
- Приставки целочисленных типов данных:
- Типы данных с плавающей точкой
- Типы данных
- Целые числа
- Числа с плавающей точкой
- Символы и строки
Тип данных bool
Первый в таблице — это тип данных bool — целочисленный тип данных, так как диапазон допустимых значений — целые числа от 0 до 255. Но как Вы уже заметили, в круглых скобочках написано — логический тип данных, и это тоже верно. Так как bool используется исключительно для хранения результатов логических выражений. У логического выражения может быть один из двух результатов true или false. true — если логическое выражение истинно, false — если логическое выражение ложно.
Но так как диапазон допустимых значений типа данных bool от 0 до 255, то необходимо было как-то сопоставить данный диапазон с определёнными в языке программирования логическими константами true и false. Таким образом, константе true эквивалентны все числа от 1 до 255 включительно, тогда как константе false эквивалентно только одно целое число — 0. Рассмотрим программу с использованием типа данных bool.
// data_type.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{ bool boolean = 25; // переменная типа bool с именем boolean if ( boolean ) // условие оператора if cout << "true = " << boolean << endl; // выполнится в случае истинности условия else cout << "false = " << boolean << endl; // выполнится в случае, если условие ложно system("pause"); return 0;
}строке 9 объявлена переменная типа bool, которая инициализирована значением 25. Теоретически после строки 9, в переменной boolean должно содержаться число 25, но на самом деле в этой переменной содержится число 1. Как я уже говорил, число 0 — это ложное значение, число 1 — это истинное значение. Суть в том, что в переменной типа bool могут содержаться два значения — 0 (ложь) или 1 (истина). Тогда как под тип данных bool отводится целый байт, а это значит, что переменная типа bool может содержать числа от 0 до 255. Для определения ложного и истинного значений необходимо всего два значения 0 и 1. Возникает вопрос: «Для чего остальные 253 значения?».
Исходя из этой ситуации, договорились использовать числа от 2 до 255 как эквивалент числу 1, то есть истина. Вот именно по этому в переменной boolean содержится число 25 а не 1. В строках 10 -13 объявлен оператор условного выбора if, который передает управление оператору в строке 11, если условие истинно, и оператору в строке 13, если условие ложно. Результат работы программы смотреть на рисунке 1.
true = 1 Для продолжения нажмите любую клавишу . . .
Рисунок 1 — Тип данных bool
К данным относится любая информация, представленная в таком виде, который позволяет автоматизировать её сбор, хранение и обработку в ЭВМ (числа, символы, биты и др.).
Данные в программе могут быть исходными (задаваемыми на входе программы) или результатами обработки (промежуточными или выходными).
Все данные – переменные и константы – принадлежат определенному типу.
С каждым типом данных связан свой диапазон значений ( количество байт под одно значение) и допустимые операции.
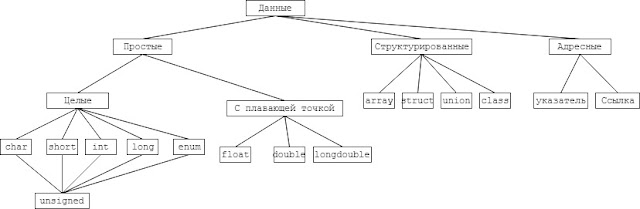
Типы данных в C/C++ разделяются на основные и производные.
К основным типам относят:
- void (пустой тип),
- int (целый тип),
- float (вещественные числа с плавающей точкой),
- double (вещественные числа с плавающей точкой двойной точности),
- char (символьный тип),
- bool – логический.
Составные типы
Для формирования других типов данных используют основные типы + так называемые спецификаторы. Типы данных, созданные на базе стандартных типов с использованием спецификаторов, называют составными типами данных. В C++ определены четыре спецификатора типов данных:
- short – короткий;
- long – длинный;
- signed-знаковый;
- unsigned-беззнаковый.
Производные типы – это:
- массивы,
- функции,
- классы,
- указатели,
- ссылки,
- структуры ,
- объединения.
Символьный тип
Данные типа char в памяти компьютера всегда занимают 1 байт. Это связано с тем, что обычно под величину символьного типа отводят столько памяти, сколько необходимо для хранения любого из 256 символов клавиатуры.
Символьный тип может быть со знаком или без знака.
В величинах со знаком signed char можно хранить значения в диапазоне от -128 до 127. Соответственно значения переменных типа unsigned char могут находиться в диапазоне
от 0 до 255.
При работе с символьными данными нужно помнить, что если в выражении встречается одиночный символ, он должен быть заключен в одинарные кавычки. Последовательность символов, то есть строка, при использовании в выражениях заключается в двойные кавычки.
Например: ‘F’ , ‘3’ , “Иван”, “235”
Целочисленный тип
Данные типа int в памяти компьютера могут занимать либо 2, 4 или 8 байт. Это зависит от разрядности процессора.
По умолчанию все целые типы считаются знаковыми, то есть спецификатор signed (знаковый ) можно не указывать.
Спецификатор unsigned (беззнаковый) позволяет представлять только положительные числа.
Диапазоны значений целочисленных типов
Вещественный тип
Диапазоны значений вещественных типов
Длина мантиссы определяет точность числа, а длина порядка его диапазон.
Данные типа float занимают 4 байт, из которых 1 двоичный разряд отводится под знак, 8 разрядов – под порядок и 23 – под мантиссу.
По-скольку старшая цифра мантиссы всегда равна 1, она не хранится.
Данные типа double занимают 8 байт, в них под порядок -11 разрядов и под мантиссу -52 разряда соответственно.
Спецификатор типа long перед именем типа double указывает, что под величину отводится 10 байт.
Логический тип
Переменная типа bool может принимать только два значения true (истина) или false (ложь).
Любое значение, не равное нулю, интерпретируется как true, а при преобразовании к целому типу принимает значение, равное 1.
Значение false представлено в памяти как 0.
Тип void (пустой)
Множество значений этого типа пусто.
Тип void используется для:
- определения функций, которые не возвращают значения;
- для указания пустого списка аргументов функции;
- как базовый тип для указателей;
- в операции приведения типов.
Объявление переменных
Переменная – это поименованный участок памяти, в котором хранится значение определенного типа.
У переменной есть имя (идентификатор) и значение.
Имя служит для обращения к области памяти, в которой хранится значение.
Имя (идентификатор) – это совокупность букв, цифр и знаков подчёркивания, задающая имя переменной, название функции или ключевое слово в программе.
Язык С/C++ чувствителен к регистру ( т.е. Sum и sum будут восприниматься как две разные переменные).
где, тип – ключевое слово, определяющее объём памяти (число байтов), выделенный для хранения значения переменной (как объекта программы), (int – целый,
float, double – вещественный,
char – символьный,
bool – логический);
имя – уникальный идентификатор переменной, задающий символический адрес объекта программы в памяти ЭВМ;
инициатор – начальное значение переменной, которое может отсутствовать в описании.
Например:
Однотипные переменные можно сгруппировать, разделив «,».
Описание переменных разного типа разделяется « ; ».
По месту обьявления переменные в языке С/С++ можно разделить на три класса:
- локальные- объявляются внутри функции и доступны только в ней;
- глобальные – описываются до всех функций и доступны из любого места программы;
- формальные параметры функций описываются в списке параметров функции.
Тип данных char
ASCII ( от англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией.
Рассмотрим программу с использованием типа данных char.
// symbols.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{ char symbol = 'a'; // объявление переменной типа char и инициализация её символом 'a' cout << "symbol = " << symbol << endl; // печать символа, содержащегося в переменной symbol char string[] = "cppstudio.com"; // объявление символьного массива (строки) cout << "string = " << string << endl; // печать строки system("pause"); return 0;
}строке 9 объявлена переменная с именем symbol, ей присвоено значение символа 'a'ASCII кодстроке 10 cout печатает символ, содержащийся в переменной symbolстроке 11 объявлен строковый массив с именем string, причём размер массива задан неявно. В строковый массив сохранена строка "cppstudio.com". Обратите внимание на то, что, когда мы сохраняли символ в переменную типа char, то после знака равно мы ставили одинарные кавычки, в которых и записывали символ. При инициализации строкового массива некоторой строкой, после знака равно ставятся двойные кавычки, в которых и записывается некоторая строка. Как и обычный символ, строки выводятся с помощью оператора coutстрока 12. Результат работы программы показан на рисунке 2.
symbol = a string = cppstudio.com Для продолжения нажмите любую клавишу . . .
Рисунок 2 — Тип данных char
Типы данных
Последнее обновление: 08.02.2023
Переменная имеет определенный тип. И этот тип определяет, какие значения может иметь переменная и сколько байт в памяти она будет занимать.
В Си определены следующие базовые типы данных:
: представляет один символ. Занимает в памяти 1 байт (8 бит). Может хранить любое значение из диапазона от -128 до 127
: представляет один символ. Занимает в памяти 1 байт (8 бит). Может хранить любой значение из
диапазона от 0 до 255: то же самое, что и char
: представляет целое число в диапазоне от –32768 до 32767. Занимает в памяти 2 байта (16 бит).
Имеет псевдонимы , и signed short int.
: представляет целое число в диапазоне от 0 до 65535. Занимает в памяти 2 байта (16 бит).
Имеет псевдоним unsigned short int.
: представляет целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита). Диапазон предельных
значений соответственно также может варьироваться от –32768 до 32767 (при 2 байтах) или от −2 147 483 648 до 2 147 483 647 (при 4 байтах).Имеет псевдонимы и
: представляет положительное целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита), и из-за этого диапазон предельных значений может
меняться: от 0 до 65535 (для 2 байт), либо от 0 до 4 294 967 295 (для 4 байт).Имеет псевдоним : то же самое, что и
: представляет целое число в диапазоне от -2 147 483 648 до 2 147 483 647. Занимает в памяти 4 байта (32 бита).
Имеет псевдонимы , signed long int и .
: представляет целое число в диапазоне от 0 до 4 294 967 295. Занимает в памяти 4 байта (32 бита).
Имеет псевдоним unsigned long int.
: представляет целое число в диапазоне от -9223372036854775807 до +9 223 372 036 854 775 807. Занимает в памяти, как правило, 8 байт (64 бита).
Имеет псевдонимы long long int, signed long long int и signed long long.
unsigned long long: представляет целое число в диапазоне от 0 до 18 446 744 073 709 551 615. Занимает в памяти, как правило, 8 байт (64 бита).
Имеет псевдоним unsigned long long int.
: представляет вещественное число одинарной точности с плавающей точкой в диапазоне +/- 3.4E-38 до 3.4E+38. В памяти занимает 4 байта (32 бита)
: представляет вещественное число двойной точности с плавающей точкой в диапазоне +/- 1.7E-308 до 1.7E+308. В памяти занимает 8 байт (64 бита)
: представляет вещественное число двойной точности с плавающей точкой в диапазоне +/- 3.4E-4932 до 1.1E+4932. В памяти занимает 10 байт (80 бит). На некоторых системах может занимать 96 и 128 бит.
: тип без значения
Целочисленные типы
Наиболее распространенным целочисленным типом является (имеет псевдонимы и ), представляет целое число
со знаком и обычно занимает 4 байта. Переменной такого типа можно передать целое число:
int age = 38; signed int number = 2; signed temps = -3;
Для определения переменной некоторого типа можно использовать все псевдонимы этого типа. Так, в примере выше определяются три переменных типа int, хотя в каждом случае используются
разные псевдонимы типа: int, signed int и signed.
Суффиксы целочисленных типов
Стоит учитывать, что любое десятичное число рассматривается по умолчанию как значение типов int/long int/long long int (в зависимости от размера)
и при присвоении переменным другим типов будет выполняться преобразование. Чтобы указать, что число явным образом представляет определенный тип, к числу добавляется определенный суффикс:
Как видно, не для всех типов есть отдельные суффиксы. И для некоторых типов можно применять несколько суффиксов. Применим суффикс. Например, если надо хранить только положительные числа, то можно взять тип . Для определения чисел этого типа применяется суффикс или :
#include <stdio.h>
int main(void)
{ unsigned number1 = 4294967294u; unsigned int number2 = 22U; printf("number1 = %u\n", number1); printf("number2 = %u\n", number2); return 0;
}При выводе таких чисел на консоль применяется спецификатор .
Стоит отметить, что мы могли бы присвоить переменной число и без суффикса и получили бы тот же самый результат:
unsigned number1 = 4294967294; // без суффикса u
unsigned int number2 = 22; // без суффикса u
printf("number1 = %u\n", number1);
printf("number2 = %u\n", number2);Зачем же нужен данный суффикс? Без этого суффикса десятичное число рассматривается как значение типов int/long int/long long int и при присвоении
переменной типа unsigned int выполняется преобразование. Используя суффикс, мы можем избежать ненужного преобразования.
Пример определения данных других типов:
#include <stdio.h>
int main(void)
{ unsigned short number1 = 1u; unsigned short int number2 = 2u; short number3 = 3; short int number4 = -4; signed short number5 = 5; signed short int number6 = -6; long number7 = -2147483648l; long int number8 = -2147483648L; signed long number9 = 2147483647l; signed long int number10 = 2147483647L; unsigned long number11 = 4294967295ul; unsigned long int number12 = 4294967295UL; long long number13 = -9223372036854775807ll; long long int number14 = 9223372036854775807ll; signed long long number15 = -9223372036854775807LL; signed long long int number16 = 9223372036854775807LL; unsigned long long number17 = 18446744073709551615ull; unsigned long long int number18 = 18446744073709551615ULL; printf("number1 = %hu\n", number1); printf("number2 = %hu\n", number2); printf("number3 = %d\n", number3); printf("number4 = %d\n", number4); printf("number5 = %d\n", number5); printf("number6 = %d\n", number6); printf("number7 = %ld\n", number7); printf("number8 = %ld\n", number8); printf("number9 = %ld\n", number9); printf("number10 = %ld\n", number10); printf("number11 = %lu\n", number11); printf("number12 = %lu\n", number12); printf("number13 = %lld\n", number13); printf("number14 = %lld\n", number14); printf("number15 = %lld\n", number15); printf("number16 = %lld\n", number16); printf("number17 = %llu\n", number17); printf("number18 = %llu\n", number18); return 0;
}Обратите внимание на спецификатор, который используется для вывода числа на консоль в функции printf():
Определение чисел в различных системах
Си позволяет определять числа в разных числовых системых. Числа в двоичной системе начинаются с символов , после которых идет набор 1 и 0, которые представляют число.
Восьмеричные числа начинаются с числа 0, за которым могут идти цифры от 0 до 7. Щестнадцатеричные числа начинаются с или ,
за которыми следуют шестнадцатеричные цифры от 0 до 9 и от A до F. Например:
#include <stdio.h>
int main(void)
{ int code1 = 0b1011; // двоичная система - число 11 int code2 = 013; // восьмеричная система - число 11 int code3 = 11; // десятичная система - число 11 int code4 = 0xB; // шестнадцатеричная система - число 11 printf("code1 = %d\n", code1); // code1 = 11 printf("code2 = %d\n", code2); // code2 = 11 printf("code3 = %d\n", code3); // code3 = 11 printf("code4 = %d\n", code4); // code4 = 11 return 0;
}В данном случае определены четыре переменных, но каждая из них хранит одно и то же число – 11, записанное в разных системах исчисления.
Числа с плавающей точкой
Числа с плавающей точкой представлены тремя типами: , , . В качестве разделителя между целой
и дробной частями применяется точка. По умолчанию все дробные числа представляют тип , который занимает 8 байт:
#include <stdio.h>
int main(void)
{ double number = 3.14159; printf("number = %f\n", number); return 0;
}Для вывода значения double на консоль используется спецификаторы и . Чтобы указать, что число представляет тип ,
применяется суффикс , а для – суффикс :
#include <stdio.h>
int main(void)
{ float number1 = 3.14f; long double number2 = 123456.789l; printf("number1 = %f\n", number1); printf("number2 = %Lf\n", number2); return 0;
}Стоит отметить, что для вывода данных типа на консоль применяется спецификатор , однако на некоторых платформах он может работать некорректно, например,
показывать 0.
Символы
Переменным типа можно присвоить один символ в одинарных кавычках:
char letter = 'A';
Здесь определяется переменная letter, которая хранит символ ‘A’. Однако в реальности переменная типа char хранит число. И когда переменной присваивается символ, она получает
числовой код этого символа из таблицы, которая сопоставляет числовые коды и символы. Наиболее распространена таблица ASCII. Она сопоставляет символы с числами от 0 до 127. Но есть и другие таблицы,
которые, как правило, эту таблицу ASCII. Например, возьмем выше определенную переменную letter и выведем ее содержимое на консоль:
#include <stdio.h>
int main(void)
{ char letter = 'A'; printf("letter: %d \n", letter); // letter: 65 printf("letter: %c \n", letter); // letter: A return 0;
}Числовой код символа ‘A’ в таблице ASCII равен 65. Для наглядности в программе два раза выводим значение переменной letter. Но в первом случае используем спецификатор %d
для вывода числового кода символа, а во втором случае применяется спецификатор %c, который позволяет вывести на консоль сам символ. То есть при выполнении программа выведет
на консоль:
Вместо символа в одинарных кавычках мы могли бы присвоить напрямую числовой код:
#include <stdio.h>
int main(void)
{ char letter = 65; printf("letter: %d \n", letter); // letter: 65 printf("letter: %c \n", letter); // letter: A return 0;
}И мы получили бы тот же самый результат.
typedef
Оператор позволяет для определенного типа псевдоним. Это может потребоваться, например, когда название некоторого типа довольно большое, и
мы хотим его сократить.
Общая форма оператора
typedef существующий_тип псевдоним
Например, зададим для типа unsigned char псевдоним BYTE:
typedef unsigned char BYTE;
И мы сможем использовать этот тип как и любой другой:
#include <stdio.h>
typedef unsigned char BYTE;
int main(void)
{ BYTE byte = 22; printf("byte = %d", byte);
}Размер типов данных
В выше приведенном списке для каждого типа указан размер, который он занимает в памяти. Однако стоит отметить, что предельные размеры для типов разработчики компиляторов могут выбирать самостоятельно, исходя из
аппаратных возможностей компьютера. Стандарт устанавливает лишь минимальные значения, которые должны быть. Например, для типов int и short минимальное
значение – 16 бит, для типа long – 32 бита. При этом размер типа long должен быть не меньше размера типа int, а размер типа int – не меньше размера типа short. Но в
целом для типов используются те размеры, которые указаны выше при описании типов данных.
Однако бывают ситуации, когда необходимо точно знать размер определенного типа. И для этого в C есть оператор ,
который возвращает размер памяти в байтах, которую занимает переменная:
#include <stdio.h>
int main(void)
{ int number = 2; printf("sizeof(number) = %d \n", sizeof(number)); return 0;
}При этом при определении переменных важно понимать, что значение переменной не должно выходить за те пределы, которые очерчены для ее типа. Например:
unsigned short int number = -65535;
Компилятор GCC при компиляции программы с этой строкой выдаст ошибку о том, что значение -65535 не входит в диапазон допустимых значений для типа
unsigned short int.
Типы данных
Последнее обновление: 13.02.2023
Каждая переменная имеет определенный тип. И этот тип определяет, какие значения может иметь переменная, какие операции с ней можно производить и сколько байт в памяти она будет занимать.
В языке C++ определены следующие базовые типы данных: логический тип , целочисленные типы, типа чисел с плавающей точкой, символьные типы. Рассмотрим эти группы по отдельности.
Логический тип
Логический тип может хранить одно из двух значений: (истинно, верно) и (неверно, ложно).
Например, определим пару переменных данного типа и выведем их значения на консоль:
#include <iostream>
int main()
{ bool isAlive {true}; bool isDead {false}; std::cout << "isAlive: " << isAlive << "\n"; std::cout << "isDead: " << isDead << "\n";
}При выводе значения типа bool преобразуются в 1 (если true) и 0 (если false). Как правило, данный тип применяется преимущество в условных выражениях, которые будут далее рассмотрены.
Значение по умолчанию для переменных этого типа – false.
Целочисленные типы
Целые числа в языке C++ представлены следующими типами:
: представляет один символ. Занимает в памяти 1 байт (8 бит).
Может хранить любой значение из диапазона от -128 до 127: представляет один символ. Занимает в памяти 1 байт (8 бит).
Может хранить любой значение из диапазона от 0 до 255: представляет один символ в кодировке ASCII. Занимает в памяти 1 байт (8 бит).
Может хранить любое значение из диапазона от -128 до 127, либо от 0 до 255Несмотря на то, что данный тип представляет тот же диапазон значений, что и вышеописанный тип
signed char, но они не эквивалентны. Типcharпредназначен для
хранения числового кода символа и в реальности может представлять какsigned byte, так иunsigned byteв зависимости от конкретного компилятора.: представляет целое число в диапазоне от –32768 до 32767. Занимает в памяти 2 байта (16 бит).
Данный тип также имеет псевдонимы , signed short int, .
: представляет целое число в диапазоне от 0 до 65535. Занимает в памяти 2 байта (16 бит).
Данный тип также имеет синоним unsigned short int.
: представляет целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита). Диапазон предельных
значений соответственно также может варьироваться от –32768 до 32767 (при 2 байтах) или от −2 147 483 648 до 2 147 483 647 (при 4 байтах).
Но в любом случае размер должен быть больше или равен размеру типа short и меньше или равен размеру типа longДанный тип имеет псевдонимы и .
: представляет положительное целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита), и из-за этого диапазон предельных значений может
меняться: от 0 до 65535 (для 2 байт), либо от 0 до 4 294 967 295 (для 4 байт).Имеет псевдоним
: в зависимости от архитектуры может занимать 4 или 8 байт и представляет целое число в диапазоне от −2 147 483 648 до 2 147 483 647 (при 4 байтах) или
от −9 223 372 036 854 775 808 до +9 223 372 036 854 775 807 (при 8 байтах). Занимает в памяти 4 байта (32 бита) или.Имеет псевдонимы , signed long int и
: представляет целое число в диапазоне от 0 до 4 294 967 295. Занимает в памяти 4 байта (32 бита).
Имеет синоним unsigned long int.
: представляет целое число в диапазоне от −9 223 372 036 854 775 808 до +9 223 372 036 854 775 807. Занимает в памяти 8 байт (64 бита).
Имеет псевдонимы long long int, signed long long int и signed long long.
unsigned long long: представляет целое число в диапазоне от 0 до 18 446 744 073 709 551 615. Занимает в памяти, как правило, 8 байт (64 бита).
Имеет псевдоним unsigned long long int.
Для представления чисел в С++ применятся целочисленные литералы со знаком или без, типа -10 или 10. Например, определим ряд переменных целочисленных типов и выведем их значения на консоль:
#include <iostream>
int main()
{ signed char num1{ -64 }; unsigned char num2{ 64 }; short num3{ -88 }; unsigned short num4{ 88 }; int num5{ -1024 }; unsigned int num6{ 1024 }; long num7{ -2048 }; unsigned long num8{ 2048 }; long long num9{ -4096 }; unsigned long long num10{ 4096 }; std::cout << "num1 = " << num1 << std::endl; std::cout << "num2 = " << num2 << std::endl; std::cout << "num3 = " << num3 << std::endl; std::cout << "num4 = " << num4 << std::endl; std::cout << "num5 = " << num5 << std::endl; std::cout << "num6 = " << num6 << std::endl; std::cout << "num7 = " << num7 << std::endl; std::cout << "num8 = " << num8 << std::endl; std::cout << "num9 = " << num9 << std::endl; std::cout << "num10 = " << num10 << std::endl;
}Но стоит отметить, что все целочисленные литералы по умолчанию представляют тип int. Так, выше переменным разных типов присваивались различные числа – 64, -64, 88, -88, 1024 и т.д.
Но все эти целочисленные литералы представляют тип int.
Однако мы можем использовать целочисленные литералы и других типов. Целочисленные литералы без знака (которые представляют unsigned-типы)
имеют суффикс или . Литералы типов long и long long имеют суффиксы
/ и / соответственно:
#include <iostream>
int main()
{ unsigned int num6{ 1024U }; // U - unsigned int long num7{ -2048L }; // L - long unsigned long num8{ 2048UL }; // UL - unsigned long long long num9{ -4096LL }; // LL - long long unsigned long long num10{ 4096ULL };// ULL - unsigned long long std::cout << "num6 = " << num6 << std::endl; std::cout << "num7 = " << num7 << std::endl; std::cout << "num8 = " << num8 << std::endl; std::cout << "num9 = " << num9 << std::endl; std::cout << "num10 = " << num10 << std::endl;
}Тем не менее использовать суффиксы необязательно, поскольку, как правило, компилятор может успешно преобразовать целочисленный литерал типа (который технически представляет тип int) к
нужному типу без потери информации.
Если число большое, то при вводе мы можем где-то ошибиться. Чтобы упростить читабельность чисел, начиная со стандарта C++14 в язык была добавлена возможность разделения разрядов числа с
помощью одинарной кавычки ‘
#include <iostream>
int main()
{ int num{ 1'234'567'890 }; std::cout << "num = " << num << "\n"; // num = 1234567890
}Различные системы исчисления
По умолчанию все стандартные целочисленные литералы представляют числа в привычной нам десятичной системе. Однако C++ также позволяет использовать и числа в других системах исчисления.
Чтобы указать, что число – шестнадцатеричное, перед числом указывается префикс или . Например:
int num1{ 0x1A}; // 26 - в десятичной
int num2{ 0xFF }; // 255 - в десятичной
int num3{ 0xFFFFFF }; //16777215 - в десятичнойЧтобы указать, что число – восьмеричное, перед числом указывается ноль . Например:
int num1{ 034}; // 26 - в десятичной
int num2{ 0377 }; // 255 - в десятичнойБинарные литералы предваряются префиксом или :
int num1{ 0b11010}; // 26 - в десятичной
int num2{ 0b11111111 }; // 255 - в десятичнойВсе эти типы литералов также поддерживают суффиксы U/L/LL:
unsigned int num1{ 0b11010U}; // 26 - в десятичной
long num2{ 0377L }; // 255 - в десятичной
unsigned long num3{ 0xFFFFFFULL }; //16777215 - в десятичнойЧисла с плавающей точкой
Для хранения дробных чисел в C++ применяются числа с плавающей точкой. Число с плавающей точкой состоит из двух частей: и .
Оба могут быть как положительными, так и отрицательными. Величина числа – это мантисса, умноженная на десять в степени экспоненты.
Например, число 365 может быть записано в виде числа с плавающей точкой следующим образом:
3.650000E02
В качестве разделителя целой и дробной частей используется символ точки. Мантисса здесь имеет семь десятичных цифр – 3.650000, показатель степени – две цифры 02. Буква означает экспоненту, после нее указывается показатель степени
(степени десяти), на которую умножается часть 3.650000 (мантисса), чтобы получить требуемое значение. То есть, чтобы вернуться к обычному десятичному представлению, нужно выполнить следующую операцию:
3.650000 × 102 = 365
Другой пример – возьмем небольшое число:
-3.650000E-03
В данном случае мы имеем дело с числом –3.65 × 10-3, что равно –0.00365. Здесь мы видим, что в зависимости от значения показателя
степени десятичная точка “плавает”. Собственно поэтому их и называют числами с плавающей точкой.
В языке C++ есть три типа для представления чисел с плавающей точкой:
: представляет вещественное число одинарной точности с плавающей точкой в диапазоне +/- 3.4E-38 до 3.4E+38. В памяти занимает 4 байта (32 бита)
: представляет вещественное число двойной точности с плавающей точкой в диапазоне +/- 1.7E-308 до 1.7E+308. В памяти занимает 8 байт (64 бита)
: представляет вещественное число двойной точности с плавающей точкой не менее 8 байт (64 бит). В зависимости от размера занимаемой памяти может отличаться
диапазон допустимых значений.
В своем внутреннем бинарном представлении каждое число с плавающей запятой состоит из одного бита знака, за которым следует фиксированное количество битов для показателя степени и набор битов для хранения мантиссы.
В числах 1 бит предназначен для хранения знака, 8 бит для экспоненты и 23 для мантиссы, что в сумме дает 32 бита.
Мантисса позволяет определить точность числа в виде 7 десятичных знаков.
В числах : 1 знаковый бит, 11 бит для экспоненты и 52 бит для мантиссы, то есть в сумме 64 бита. 52-разрядная мантисса позволяет определить
точность до 16 десятичных знаков.
Для типа расклад зависит от конкретного компилятора и реализации этого типа данных. Большинство компиляторов предоставляют точность до
18 – 19 десятичных знаков (64-битная мантисса), в других же (как например, в Microsoft Visual C++) long double аналогичен типу double.
В C++ литералы чисел с плавающими точками представлены дробными числами, которые в качестве разделителя целой и дробной частей применяют точку:
double num {10.45};Даже если переменной присваивается целое число, чтобы показать, что мы присваиваем число с плавающей точкой, применяется точка:
double num1{ 1 }; // 1 - целочисленный литерал
double num2{ 1. }; //1. - литерал числа с плавающей точкойТак, здесь число 1. представляет литерал числа с плавающей точкой, и в принципе аналогичен 1.0.
По умолчанию все такие числа с точкой расцениваются как числа типа double. Чтобы показать, что число представляет другой тип, для float применяется суффикс
/, а для long double – /:
float num1{ 10.56f }; // float
long double num2{ 10.56l }; // long doubleВ качестве альтернативы также можно применять экспоненциальную запись:
double num1{ 5E3 }; // 5E3 = 5000.0
double num2{ 2.5e-3 }; // 2.5e-3 = 0.0025Размеры типов данных
При перечислении типов данных указывался размер, который он занимает в памяти. Но стандарт языка устанавливает лишь минимальные значения, которые должны быть. Например, для типов int и short минимальное
значение – 16 бит, для типа long – 32 бита, для типа long double – 64 разряда. При этом размер типа long должен быть не меньше размера типа int, а размер типа int – не меньше размера типа short,
а размер типа long double должен быть не меньше double. А разработчики компиляторов могут выбирать предельные размеры для типов самостоятельно,
исходя из аппаратных возможностей компьютера.
К примеру, компилятор g++ Windows для long double использует 16 байт.
А компилятор в Visual Studio, который также работает под Windows, и clang++ под Windows для long double используют 8 байт. То есть даже в рамках одной платформы разные компиляторы могут
по разному подходить к размерам некоторых типов данных. Но в целом используются те размеры, которые указаны выше при описании типов данных.
Однако бывают ситуации, когда необходимо точно знать размер определенного типа. И для этого в С++ есть оператор ,
который возвращает размер памяти в байтах, которую занимает переменная:
#include <iostream>
int main()
{ long double number {2}; std::cout << "sizeof(number) =" << sizeof(number);
}Консольный вывод при компиляции в g++:
Символьные типы
В C++ есть следующие символьные типы данных:
: представляет один символ в кодировке ASCII. Занимает в памяти 1 байт (8 бит).
Может хранить любое значение из диапазона от -128 до 127, либо от 0 до 255: представляет расширенный символ. На Windows занимает в памяти 2 байта (16 бит), на Linux – 4 байта (32 бита).
Может хранить любой значение из диапазона от 0 до 65 535 (при 2 байтах), либо от 0 до 4 294 967 295 (для 4 байт): представляет один символ в кодировке Unicode. Занимает в памяти 1 байт. Может хранить любой значение из диапазона от 0 до 256
: представляет один символ в кодировке Unicode. Занимает в памяти 2 байта (16 бит). Может хранить любой значение из диапазона от 0 до 65 535
: представляет один символ в кодировке Unicode. Занимает в памяти 4 байта (32 бита). Может хранить любой значение из диапазона от 0 до 4 294 967 295
char
Переменная типа хранит числовой код одного символа и занимает один байт. Стандарт языка С++
не определяет кодировку символов, которая будет использоваться для символов char, поэтому производители компиляторов могут выбирать любую кодировку, но обычно это ASCII.
В качестве значения переменная типа char может принимать один символ в одинарных кавычках, либо числовой код символа:
#include <iostream>
int main()
{ char a1 {'A'}; char a2 {65}; std::cout << "a1: " << a1 << std::endl; std::cout << "a2: " << a2 << std::endl;
}В данном случае переменные a1 и a2 будут иметь одно и то же значение, так как 65 – это числовой код символа “A” в таблице ASCII. При выводе на консоль
с помощью cout по умолчанию отображается символ.
Кроме того, в C++ можно использовать специальные управляющие последовательности, которые предваряются слешем и которые интерпретируются особым образом. Например,
“\n” представляет перевод строки, а “\t” – табуляцию.
Однако ASCII обычно подходит для наборов символов языков, которые используют латиницу. Но если необходимо работать с символами для нескольких языков одновременно или с символами языков, отличных от английского, 256-символьных кодов может быть недостаточно.
И в этом случае применяется .
Unicode (Юникод) — это стандарт, который определяет набор символов и их кодовых точек, а также несколько различных кодировок для этих кодовых точек. Наиболее часто используемые кодировки: UTF-8, UTF-16 и UTF-32.
Разница между ними заключается в том, как представлена кодовая точка символа; числовое же значение кода для любого символа остается одним и тем же
в любой из кодировок. Основные отличия:
представляет символ как последовательность переменной длины от одного до четырех
байт. Набор символов ASCII появляется в UTF-8 как однобайтовые коды, которые имеют
те же значения кодов, что и в ASCII. UTF-8 на сегодняшний день является самой популярной кодировкой Unicode.представляет символы как одно или два 16-битных значения.
представляет все символы как 32-битные значения
В C++ есть четыре типа для хранения символов Unicode: , , и
(char16_t и char32_t были добавлены в C+11, а char8_t – в C++20).
wchar_t
Тип — это основной тип, предназначенный для наборов символов, размер которых выходит за пределы одного байта.
Собственно отсюда и его название: wchar_t – wide (широкий) char. происходит от широкого символа, потому что этот символ «шире», чем
обычный однобайтовый символ. Значения wchar_t определяются также как и символы char за тем исключением, что они предваряются символов “L”:
wchar_t a1 {L'A'};Также можно передать код символа
wchar_t a1 {L'A'};Значение, заключенное в одинарные кавычки, представляет собой шестнадцатеричный код символа. Обратная косая черта указывает на начало управляющей последовательности, а
x после обратной косой черты означает, что код шестнадцатеричный.
Стоит учитывать, что для вывода на консоль символов wchar_t следует использовать не std::cout, а поток :
#include <iostream>
int main()
{ char h = 'H'; wchar_t i {L'i'}; std::wcout << h << i <<'\n';
}При этом поток std::wcout может работать как с char, так и с wchar_t. А поток std::cout для переменной wchar_t вместо символа будет выводить его числовой код.
Проблема с типом wchar_t заключается в том, что его размер сильно зависит от реализации и применяемой кодировки. Кодировка обычно соответствует
предпочтительной кодировке целевой платформы. Так, для Windows wchar_t обычно имеет ширину 16 бит и кодируется с помощью UTF-16.
Большинство других платформ устанавливают размер в 32 бита, а в качестве кодировки применяют UTF-32. С одной стороны, это позволяет больше соответствовать конкретной платформе.
Но с другой стороны, затрудняет написание кода, переносимого на разные платформы. Поэтому в общем случае часто рекомендуется использовать типы , и . Значения этих типов предназначены для хранения символов в кодировке UTF-8,
UTF-16 или UTF-32 соответственно, а их размеры одинаковы на всех распространенных платформах.
Для определения символов типов , и применяются соответственно префиксы u8, u и U:
char8_t c{ u8'l' };
char16_t d{ u'l' };
char32_t e{ U'o' };Стоит отметить, что для вывода на консоль значений char8_t/char16_t/char32_t пока нет встроенных инструментов типа std:cout/std:wcout.
Спецификатор auto
Иногда бывает трудно определить тип выражения. В этом случае можно предоставить компилятору самому выводить тип объекта.
И для этого применяется спецификатор . При этом если мы определяем переменную со спецификатором auto,
эта переменная должна быть обязательно инициализирована каким-либо значением:
auto number = 5; // number имеет тип int
auto sum {1234.56}; // sum имеет тип double
auto distance {267UL}; // distance имеет тип unsigned longНа основании присвоенного значения компилятор выведет тип переменной. Неинициализированные переменные со спецификатором auto не допускаются:
auto number;
Целочисленные типы данных
Целочисленные типы данных используются для представления чисел. В таблице 1 их аж шесть штук: short int, unsigned short int, int, unsigned int, long int, unsigned long int. Все они имеют свой собственный размер занимаемой памяти и диапазоном принимаемых значений. В зависимости от компилятора, размер занимаемой памяти и диапазон принимаемых значений могут изменяться. В таблице 1 все диапазоны принимаемых значений и размеры занимаемой памяти взяты для компилятора MVS2010. Причём все типы данных в таблице 1 расположены в порядке возрастания размера занимаемой памяти и диапазона принимаемых значений. Диапазон принимаемых значений, так или иначе, зависит от размера занимаемой памяти. Соответственно, чем больше размер занимаемой памяти, тем больше диапазон принимаемых значений. Также диапазон принимаемых значений меняется в случае, если тип данных объявляется с приставкой unsigned — без знака. Приставка unsigned говорит о том, что тип данных не может хранить знаковые значения, тогда и диапазон положительных значений увеличивается в два раза, например, типы данных short int и unsigned short int.
Приставки целочисленных типов данных:
short — приставка укорачивает тип данных, к которому применяется, путём уменьшения размера занимаемой памяти;
long — приставка удлиняет тип данных, к которому применяется, путём увеличения размера занимаемой памяти;
unsigned (без знака) — приставка увеличивает диапазон положительных значений в два раза, при этом диапазон отрицательных значений в таком типе данных храниться не может.
Так, что, по сути, мы имеем один целочисленный тип для представления целых чисел — это тип данных int. Благодаря приставкам short, long, unsigned появляется некоторое разнообразие типов данных int, различающихся размером занимаемой памяти и (или) диапазоном принимаемых значений.
Типы данных с плавающей точкой
В С++ существуют два типа данных с плавающей точкой: float и double. Типы данных с плавающей точкой предназначены для хранения чисел с плавающей точкой. Типы данных float и double могут хранить как положительные, так и отрицательные числа с плавающей точкой. У типа данных float размер занимаемой памяти в два раза меньше, чем у типа данных double, а значит и диапазон принимаемых значений тоже меньше. Если тип данных float объявить с приставкой long, то диапазон принимаемых значений станет равен диапазону принимаемых значений типа данных double. В основном, типы данных с плавающей точкой нужны для решения задач с высокой точностью вычислений, например, операции с деньгами.
Итак, мы рассмотрели главные моменты, касающиеся основных типов данных в С++. Осталось только показать, откуда взялись все эти диапазоны принимаемых значений и размеры занимаемой памяти. А для этого разработаем программу, которая будет вычислять основные характеристики всех, выше рассмотренных, типов данных.
// data_types.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
// библиотека манипулирования вводом/выводом
#include <iomanip>
// заголовочный файл математических функций
#include <cmath>
using namespace std;
int main(int argc, char* argv[])
{ cout << " data type " << "byte" << " " << " max value " << endl // заголовки столбцов << "bool = " << sizeof(bool) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных bool*/ << (pow(2,sizeof(bool) * 8.0) - 1) << endl << "char = " << sizeof(char) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных char*/ << (pow(2,sizeof(char) * 8.0) - 1) << endl << "short int = " << sizeof(short int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных short int*/ << (pow(2,sizeof(short int) * 8.0 - 1) - 1) << endl << "unsigned short int = " << sizeof(unsigned short int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных unsigned short int*/ << (pow(2,sizeof(unsigned short int) * 8.0) - 1) << endl << "int = " << sizeof(int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных int*/ << (pow(2,sizeof(int) * 8.0 - 1) - 1) << endl << "unsigned int = " << sizeof(unsigned int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных unsigned int*/ << (pow(2,sizeof(unsigned int) * 8.0) - 1) << endl << "long int = " << sizeof(long int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных long int*/ << (pow(2,sizeof(long int) * 8.0 - 1) - 1) << endl << "unsigned long int = " << sizeof(unsigned long int) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных undigned long int*/ << (pow(2,sizeof(unsigned long int) * 8.0) - 1) << endl << "float = " << sizeof(float) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных float*/ << (pow(2,sizeof(float) * 8.0 - 1) - 1) << endl << "double = " << sizeof(double) << " " << fixed << setprecision(2)
/*вычисляем максимальное значение для типа данных double*/ << (pow(2,sizeof(double) * 8.0 - 1) - 1) << endl; system("pause"); return 0;
}Данная программа выложена для того, чтобы Вы смогли просмотреть характеристики типов данных в своей системе. Не стоит разбираться в коде, так как в программе используются управляющие операторы, которые Вам, вероятнее всего, ещё не известны. Для поверхностного ознакомления с кодом программы, ниже поясню некоторые моменты. Оператор sizeof() вычисляет количество байт, отводимое под тип данных или переменную. Функция pow(x,y)хy, данная функция доступна из заголовочного файла <cmath>fixedsetprecision() доступны из заголовочного файла <iomanip>манипуляторfixed, передаёт в поток вывода значения в фиксированной форме. Манипулятор setprecision(n)n знаков после запятой. Максимальное значение некоторого типа данных вычисляется по такой формуле:
max_val_type = 2^(b * 8 - 1) - 1; // для типов данных с отрицательными и положительными числами // где, b - количество байт выделяемое в памяти под переменную с таким типом данных // умножаем на 8, так как в одном байте 8 бит // вычитаем 1 в скобочках, так как диапазон чисел надо разделить надвое для положительных и отрицательных значений // вычитаем 1 в конце, так как диапазон чисел начинается с нуля // типы данных с приставкой unsigned max_val_type = 2^(b * 8 ) - 1; // для типов данных только с положительными числами // пояснения к формуле аналогичные, только в скобочка не вычитается единица
Пример работы программы можно увидеть на рисунке 3. В первом столбце показаны основные типы данных в С++, во втором столбце размер памяти, отводимый под каждый тип данных и в третьем столбце — максимальное значение, которое может содержать соответствующий тип данных. Минимальное значение находится аналогично максимальному. В типах данных с приставкой unsigned минимальное значение равно 0.
data type byte max value bool = 1 255.00 char = 1 255.00 short int = 2 32767.00 unsigned short int = 2 65535.00 int = 4 2147483647.00 unsigned int = 4 4294967295.00 long int = 4 2147483647.00 unsigned long int = 4 4294967295.00 float = 4 2147483647.00 double = 8 9223372036854775808.00 Для продолжения нажмите любую клавишу . . .
Рисунок 3 — Типы данных С++
Если, например, переменной типа short int присвоить значение 33000, то произойдет переполнение разрядной сетки, так как максимальное значение в переменной типа short int это 32767. То есть в переменной типа short int сохранится какое-то другое значение, скорее всего будет отрицательным. Раз уж мы затронули тип данных int, стоит отметить, что можно опускать ключевое слово int и писать, например, просто short. Компилятор будет интерпретировать такую запись как short int. Тоже самое относится и к приставкам long и unsigned. Например:
// сокращённая запись типа данных int short a1; // тоже самое, что и short int long a1; // тоже самое, что и long int unsigned a1; // тоже самое, что и unsigned int unsigned short a1; // тоже самое, что и unsigned short int
Типы данных
Последнее обновление: 28.09.2020

Одной из основных особенностей Java является то, что данный язык является строго типизированным. А это значит, что каждая переменная и константа
представляет определенный тип и данный тип строго определен. Тип данных определяет диапазон значений, которые может хранить переменная или константа.
Итак, рассмотрим систему встроенных базовых типов данных, которая используется для создания переменных в Java. А она представлена следующими типами.
: хранит значение
trueилиfalseboolean isActive = false; boolean isAlive = true;
: хранит целое число от
-128до127и занимает 1 байтbyte a = 3; byte b = 8;
: хранит целое число от
-32768до32767и занимает 2 байтаshort a = 3; short b = 8;
: хранит целое число от
-2147483648до2147483647и занимает 4 байтаint a = 4; int b = 9;
: хранит целое число от
–9 223 372 036 854 775 808до9 223 372 036 854 775 807и занимает
8 байтlong a = 5; long b = 10;
: хранит число с плавающей точкой от
±4.9*10-324до±1.7976931348623157*10308и
занимает 8 байтdouble x = 8.5; double y = 2.7;
В качестве разделителя целой и дробной части в дробных литералах используется точка.
: хранит число с плавающей точкой от
-3.4*1038до3.4*1038и
занимает 4 байтаfloat x = 8.5F; float y = 2.7F;
: хранит одиночный символ в кодировке UTF-16 и занимает 2 байта, поэтому диапазон хранимых значений от
0до65535
При этом переменная может принимать только те значения, которые соответствуют ее типу. Если переменная представляет целочисленный тип, то она не может хранить дробные числа.
Целые числа
Все целочисленные литералы, например, числа 10, 4, -5, воспринимаются как значения типа , однако мы можем присваивать целочисленные литералы
другим целочисленным типам: , , . В этом случае Java автоматически осуществляет соответствующие
преобразования:
byte a = 1; short b = 2; long c = 2121;
Однако если мы захотим присвоить переменной типа long очень большое число, которое выходит за пределы допустимых значений для типа int,
то мы столкнемся с ошибкой во время компиляции:
long num = 2147483649;
Здесь число 2147483649 является допустимым для типа long, но выходит за предельные значения для типа int. И так как все целочисленные
значения по умолчанию расцениваются как значения типа int, то компилятор укажет нам на ошибку. Чтобы решить проблему, надо добавить к числу суффикс
или , который указывает, что число представляет тип long:
long num = 2147483649L;
Как правило, значения для целочисленных переменных задаются в десятичной системе счисления, однако мы можем применять и другие системы счисления.
Например:
int num111 = 0x6F; // 16-теричная система, число 111 int num8 = 010; // 8-ричная система, число 8 int num13 = 0b1101; // 2-ичная система, число 13
Для задания шестнадцатеричного значения после символов указывается число в шестнадцатеричном формате.
Таким же образом восьмеричное значение указывается после символа , а двоичное значение – после символов .
Также целые числа поддерживают разделение разрядов числа с помощью знака подчеркивания:
int x = 123_456; int y = 234_567__789; System.out.println(x); // 123456 System.out.println(y); // 234567789
Числа с плавающей точкой
При присвоении переменной типа float дробного литерала с плавающей точкой, например, 3.1, 4.5 и т.д., Java автоматически рассматривает этот литерал как значение типа double.
И чтобы указать, что данное значение должно рассматриваться как float, нам надо использовать суффикс f:
float fl = 30.6f; double db = 30.6;
И хотя в данном случае обе переменных имеют практически одно значения, но эти значения будут по-разному рассматриваться и будут занимать разное место в памяти.
Символы и строки
В качестве значения переменная символьного типа получает одиночный символ, заключенный в одинарные кавычки: char ch='e';.
Кроме того, переменной символьного типа также можно присвоить целочисленное значение от 0 до 65535. В этом случае
переменная опять же будет хранить символ, а целочисленное значение будет указывать на номер символа в таблице символов Unicode (UTF-16). Например:
char ch=102; // символ 'f' System.out.println(ch);
Еще одной формой задания символьных переменных является шестнадцатеричная форма: переменная получает значение в шестнадцатеричной форме,
которое следует после символов “\u”. Например, char ch='\u0066'; опять же будет хранить символ ‘f’.
Символьные переменные не стоит путать со строковыми, ‘a’ не идентично “a”. Строковые переменные представляют объект String, который
в отличие от char или int не является примитивным типом в Java:
String hello = "Hello..."; System.out.println(hello);
Кроме собственно символов, которые представляют буквы, цифры, знаки препинания, прочие символы, есть специальные наборы символов, которые
называют управляющими последовательностями. Например, самая популярная последовательность – “\n”. Она выполняет перенос на следующую строку. Например:
String text = "Hello \nworld"; System.out.println(text);
Результат выполнения данного кода:
В данном случае последовательность \n будет сигналом, что необходимо сделать перевод на следующую строку.
String text = "Вот мысль, которой весь я предан,\n"+ "Итог всего, что ум скопил.\n"+ "Лишь тот, кем бой за жизнь изведан,\n"+ "Жизнь и свободу заслужил."; System.out.println(text);
С помощью операции + мы можем присоединить к одному тексту другой, причем продолжение текста может располагаться на следующей строке.
Чтобы при выводе текста происходил перенос на следующую строку, применяется последовательность \n.
Результат выполнения данного кода:
Вот мысль, которой весь я предан, Итог всего, что ум скопил. Лишь тот, кем бой за жизнь изведан, Жизнь и свободу заслужил.
Текстовые блоки, которые появились в JDK15, позволяют упростить написание многострочного текста:
String text = """ Вот мысль, которой весь я предан, Итог всего, что ум скопил. Лишь тот, кем бой за жизнь изведан, Жизнь и свободу заслужил. """; System.out.println(text);
Весь текстовый блок оборачивается в тройные кавычки, при этом не надо использовать соединение строк или последовательность \n для их переноса. Результат
выполнения программы будет тем же, что и в примере выше.






